text-analysis
Session on text analysis with NLTK, including discussion of cleaning data, creating text corpora, and analyzing texts programmatically.
| «< Previous | Next »> |
Built-In Python Functions
We will now turn our attention away from the NLTK library and work with our text using the built-in Python functions—the ones that come included with the Python language, rather than the NLTK library.
Types vs. tokens
First, let’s find out how many times a given word appears in the corpus. In this case (and all cases going forward), our text will be treated as a list of words. Therefore, we will use the ‘count’ function. We could just as easily do this with a text editor, but performing this in Python allows us to save it to a variable and then utilize this statistic in other calculations (for example, if we want to know what percentage of words in a corpus are ‘lol’, we would need a count of the ‘lol’s). In the next cell, type:
text1.count("whale")
We see that “whale” occurs 906 times, but that seems a little low. Let’s check on “Whale” and see how often that appears:
text1.count("Whale")
“Whale” with a capital “W” appears 282 times. This is a problem for us—we actually want them to be collapsed into one word, since “whale” and “Whale” really are the same for our purposes. We will deal with that in a moment. For the time being, we will accept that we have two entries for “whale.”
This gets at a distinction between type and token. “Whale” and “whale” are different types (as of now) because they do not match identically. Every instance of “whale” in the corpus is another token - it is an instance of the type, “whale.” Therefore, there are 906 tokens of “whale” in our corpus.
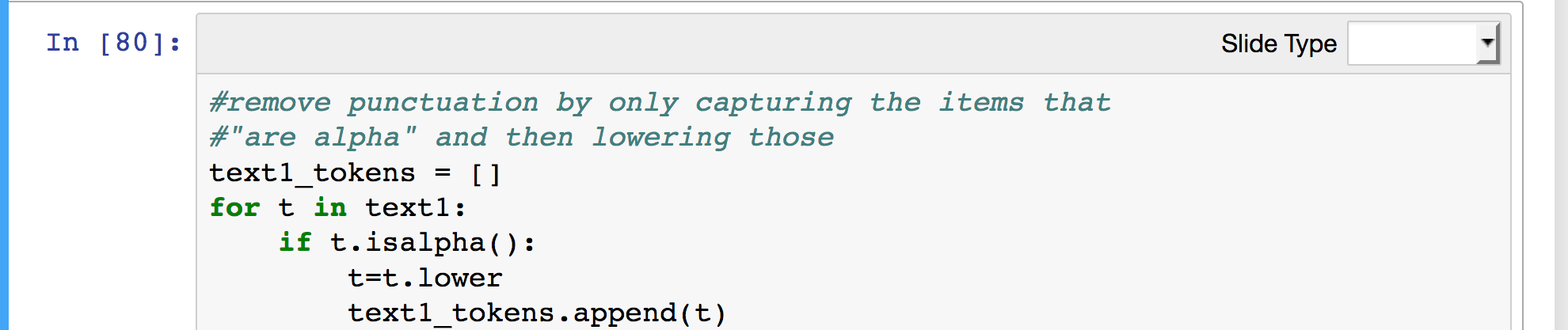
Let’s fix this by making all of the words lowercase. We will make a new list of words, and call it text1_tokens. We will fill this list with all the words in text1, but in their lowercase form. Python has a built-in function, lower() that takes all letters and makes them lowercase. In this same step, we are going to do a kind of tricky move, and only keep the words that are alphabetical and pass over anything that is punctuation or numbers. There is a built-in function, isalpha(), that will allow is to save only those words that are made of letters. If isalpha() is true, we’ll make the word lowercase, and keep the word. If not, we’ll pass over it and move to the next one.
Type the following code into a new cell in your notebook. Pay special attention to the indentation, which must appear as below.
text1_tokens = []
for t in text1:
if t.isalpha():
t = t.lower()
text1_tokens.append(t)
Another way to perform the same action more tersely is to use what’s called a list comprehension. A list comprehension is a shorter, faster way to write a for-loop, but is syntactically a little more difficult to read (for a human). But, in this case, it’s much faster to process:
text1_tokens= [t.lower() for t in text1 if t.isalpha()]
Great! Now text1_tokens is a list of all of the tokens in our corpus, with the punctuation removed, and all the words in lowercase.
Now we want to know how many words there are in our corpus—that is, how many tokens in total. Therefore, we want to ask, “What is the length of that list of words?” Python has a built-in len function that allows you to find out the length of many types. Pass it a list, and it will tell you how many items are in the list. Pass it a string, and it will tell you how many characters are in the string. Pass it a dictionary, and it will tell you how many items are in the dictionary. In the next cell, type:
len(text1_tokens)
Just for comparison, check out how many words were in “text1” - before we removed the punctuation and the numbers.
len(text1)
We see there are over 218,000 words in Moby Dick (including metadata). But this is the number of words total—we want to know the number of unique words. That is, we want to know how many types, not just how many tokens.
In order to get unique words, rather than just all words in general, we will make a set from the list. Sets in Python work just like they do in math, it’s all the unique values, with any duplicate items removed.
So let’s find out the length of our set. just like in math, we can also nest our functions. So, rather than saying x=set(text1_tokens) and then finding the length of x, we can do it all in one step.
len(set(text1_tokens))
Great! Now we can calculate the lexical density of Moby Dick. Statistical studies have shown that lexical density (the number of unique words per total words) is a good metric to approximate lexical diversity— the range of vocabulary an author uses. For our first pass at lexical density, we will simply divide the number of unique words by the total number of words:
len(set(text1_tokens))/len(text1_tokens)
If we want to use this metric to compare texts, we immediately notice a problem. Lexical density is dependent upon the length of a text and therefore is strictly a comparative measure. It is possible to compare 100 words from one text to 100 words from another, but because language is finite and repetitive, it is not possible to compare 100 words from one to 200 words from another. Even with these restrictions, lexical density is a useful metric in grade level estimations, vocabulary use and genre classification, and a reasonable proxy for lexical diversity.
Let’s take this constraint into account by working with only the first 10,000 words of our text. First we need to slice our list, returning the words in position 0 to position 9,999 (we’ll actually write it as “up to, but not including” 10,000).
text1_slice = text1_tokens[0:10000]
Now we can do the same calculation we did above:
len(set(text1_slice)) / len(text1_slice)
This is a much higher number, though the number itself is arbitrary. When comparing different texts, this step is essential to get an accurate measure.
If we wanted to perform the same set of steps with Sense and Sensibility, we could do the following:
- Make all the words lowercase and remove punctuation.
- Make a slice of the first 10,000 words.
- Calculate lexical density by dividing the length of the set of the slice by the length of the slice.
After taking these steps to find Austen’s lexical density, we could compare Melville’s range of vocabulary to Austen’s.
| «< Previous | Next »> |